Step-by-step guide to build your own ‘mini IMDB’ database
How to use simple Python libraries and built-in capabilities to scrape the web for movie information and store them in a local SQLite database.

Often
after a few introductory courses in Python, beginners wonder how to
write a cool Python program which demonstrates somewhat advanced
capabilities of the language such as web scraping or database
manipulation. In this article, I will show how to use simple Python
libraries and built-in capabilities to scrape the web for movie
information and store them in a local SQLite database, which can later
be queried for data analytics with movie info. Think of this as a
project to build your own mini IMDB database!
This type of data engineering task — gathering from web and building a database connection — is often the first step in a data analytics project. Before you do any cool predictive modeling, you need to master this step. This step is often messy and unstructured i.e. there is no one-shot formula or one-stop shop library which does it all for you. So, you have to extract the data from web, examine its structure and build your code to flawlessly crawl through it.
Specifically, this demo will show the usage of following features,
- Python urllib library
- Web API service (with a secret key) for retrieving data
- Python json library
- Python OS module
- Python SQLite library
Brief descriptions of these are given below,
Python urllib module
The gateway from Python to web is done through urllib module. It is a Python module for fetching URLs (Uniform Resource Locators). It offers a very simple interface, in the form of the urlopen
function. This is capable of fetching URLs using a variety of different
protocols. It also offers a slightly more complex interface for
handling common situations — like basic authentication, cookies, proxies
and so on. These are provided by objects called handlers and openers.
Web API service (with a secret key) for retrieving data
Web
scraping is often done by API services hosted by external websites.
Think of them as repository or remote database which you can query by
sending search string from your own little program. In this particular
example, we will take help from Open Movie Database (OMDB) website
which gives an API key to registered users for downloading information
about movies. Because it is a free service, they have a restriction of
1000 requests per day. Note, you have to register on their website and
get your own API key for making request from your Python program.
The
data obtained from this API service comes back as a JSON file.
Therefore, we need to parse/convert the JSON file into a Python object,
which we can work with easily.
Python json module
JSON (JavaScript Object Notation)
is a lightweight data-interchange format. It is easy for humans to read
and write. It is easy for machines to parse and generate. It is based
on a subset of the JavaScript Programming Language, Standard ECMA-262 3rd Edition — December 1999.
JSON is a text format that is completely language independent but uses
conventions that are familiar to programmers of the C-family of
languages, including C, C++, C#, Java, JavaScript, Perl, Python, and
many others. These properties make JSON an ideal data-interchange
language.
The json library
can parse JSON pages from strings or files. The library parses JSON
into a Python dictionary or list. It can also convert Python
dictionaries or lists into JSON strings. It is an extremely useful
module and very simple to learn. This module is likely to be used in any
Python based web data analytics program as the majority of webpages
nowadays use JSON as primary object type while returning data.
Python OS module
This
module provides a portable way of using operating system dependent
functionality. If you just want to read or write a file see
open(), if you want to manipulate paths, see the os.path module, and if you want to read all the lines in all the files on the command line see the fileinput module. For creating temporary files and directories see the tempfile module, and for high-level file and directory handling see the shutil module. In this demo, we will use OS module methods for checking existing directory and manipulate files to save some data.SQLite and Python SQLite3
SQLite
is a C library that provides a lightweight disk-based database that
doesn’t require a separate server process and allows accessing the
database using a nonstandard variant of the SQL query language. Some
applications can use SQLite for internal data storage. It’s also
possible to prototype an application using SQLite and then port the code
to a larger database such as PostgreSQL or Oracle. The sqlite3 module of Python provides a SQL interface compliant with the DB-API 2.0 specification.
Main Flow of the Program
The flow of the program is shown below. Please note that the boiler plate code is available in my Github repository. Please download/fork/star if you like it.
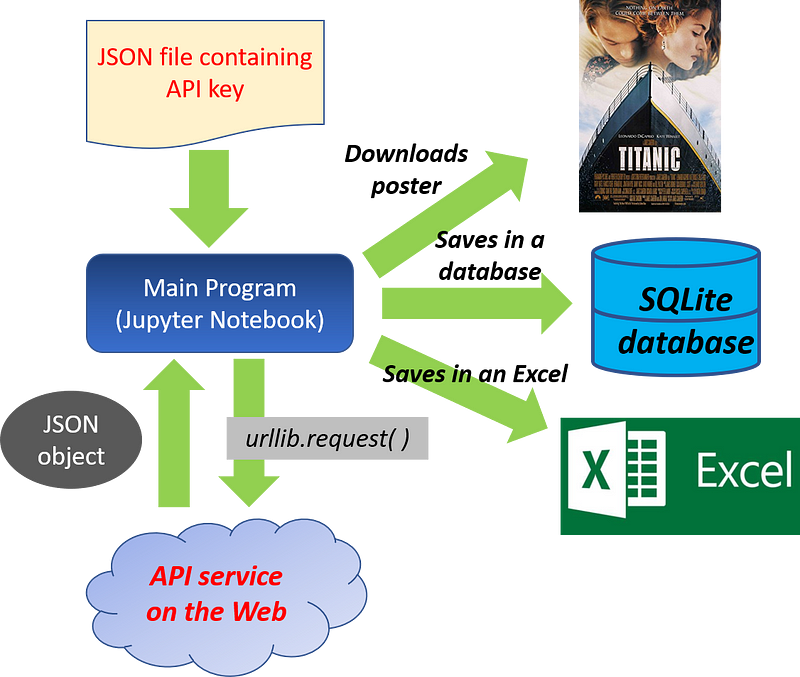
The
basic idea is to send request to external API with a movie title that
is entered by the user. The program then tries to download the data and
if successful, prints it out.
def search_movie(title):
if len(title) < 1 or title==’quit’:
print(“Goodbye now…”)
return None
try:
url = serviceurl + urllib.parse.urlencode({‘t’: title})+apikey
print(f’Retrieving the data of “{title}” now… ‘)
uh = urllib.request.urlopen(url)
data = uh.read()
json_data=json.loads(data)
if json_data[‘Response’]==’True’:
print_json(json_data)
except urllib.error.URLError as e:
print(f"ERROR: {e.reason}")
Just for example, the JSON file looks like following,
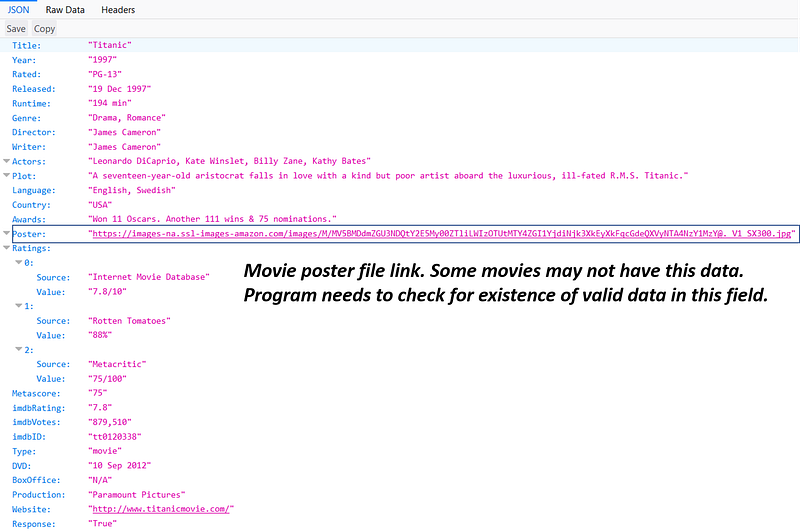
If
the program finds a link to an image file for the poster of the movie,
it asks the user if (s)he wants to download it. If user says OK, it
downloads the image file to a local directory with the movie title as
file name.
# Asks user whether to download the poster of the movie
if json_data['Poster']!='N/A':
poster_yes_no=input ('Poster of this movie can be downloaded. Enter "yes" or "no": ').lower()
if poster_yes_no=='yes':
save_poster(json_data)
Next,
it asks the user if (s)he wants to save some basic information about
the movie in a local database. If user gives the nod, it creates or
inserts into a SQLite database a subset of the downloaded movie
information.
#Asks user whether to save the movie information in a local database
save_database_yes_no=input ('Save the movie info in a local database? Enter "yes" or "no": ').lower()
if save_database_yes_no=='yes':
save_in_database(json_data)
Here is the function definition to save in the database.
The notebook also contains a function to save the information in an Excel file from an existing database.
A word about the secret API key
You
will notice that the program uses a secret API key for accessing the
data. This key can be obtained freely by going to OMDB website and be
used for up to 1000 times a day. It is a very common practice to use a
secret (user-specific) key for web scraping. The way I protect the
integrity of my personal API key is that I create a small JSON file in
the same directory of the Jupyter notebook, called APIkeys.json.
The content of this file is hidden from the external user who will see
my code. My Jupyter notebook reads this JSON file as a dictionary and
copies the key corresponding to the movie website and appends that to
the encoded URL request string that is sent by the
urllib.request method.with open(‘APIkeys.json’) as f:
keys = json.load(f)
omdbapi = keys[‘OMDBapi’]
serviceurl = 'http://www.omdbapi.com/?' apikey = '&apikey='+omdbapi
Summary
This
article goes over a demo Python notebook to illustrate how to retrieve
basic information about movies using a free API service and to save the
movie posters and the downloaded information in a lightweight SQLite
database.
Above all, it demonstrates simple utilization of Python libraries such as urllib, json, and sqlite3, which are extremely useful (and powerful) tools for data analytics/ web data mining tasks.
I
hope readers can benefit from the provided Notebook file and build upon
it as per their own requirement and imagination. For more web data
analytics notebooks, please see my repository.
If you have any questions or ideas to share, please contact the author at tirthajyoti[AT]gmail.com. Also you can check author’s GitHub repositories
for other fun code snippets in Python, R, or MATLAB and machine
learning resources. If you are, like me, passionate about machine
learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.
https://towardsdatascience.com/step-by-step-guide-to-build-your-own-mini-imdb-database-fc39af27d21b



Comments
Post a Comment