Analyzing my Google Location History
I recently read this article on how to create a heat-map from your Google Location History data. Trying it out myself, I got some amazing results:

The
large red circles represent the cities I have spent a significant
amount of time. The purple shade in different places represents places I
had travelled to or passed through while on a train journey.
My
previous phone had some GPS issues, which was leading to my location
being shown in Arizona, USA!. Surprisingly (or not?) it even gave a
proof of that!

All
this was really cool to look at, but I really wanted to dive in and get
some more insights into my travelling patterns throughout the years.
Data Pre-Processing
Like
most data science problems, data pre-processing was definitely the pain
point. The data was in a JSON format where the meaning of different
attributes wasn’t very clear.
Data Extraction
{'timestampMs': '1541235389345',
'latitudeE7': 286648226,
'longitudeE7': 773296344,
'accuracy': 22,
'activity': [{'timestampMs': '1541235388609',
'activity': [{'type': 'ON_FOOT', 'confidence': 52},
{'type': 'WALKING', 'confidence': 52},
{'type': 'UNKNOWN', 'confidence': 21},
{'type': 'STILL', 'confidence': 7},
{'type': 'RUNNING', 'confidence': 6},
{'type': 'IN_VEHICLE', 'confidence': 5},
{'type': 'ON_BICYCLE', 'confidence': 5},
{'type': 'IN_ROAD_VEHICLE', 'confidence': 5},
{'type': 'IN_RAIL_VEHICLE', 'confidence': 5},
{'type': 'IN_TWO_WHEELER_VEHICLE', 'confidence': 3},
{'type': 'IN_FOUR_WHEELER_VEHICLE', 'confidence': 3}]}]},
{'timestampMs': '1541235268590',
'latitudeE7': 286648329,
'longitudeE7': 773296322,
'accuracy': 23,
'activity': [{'timestampMs': '1541235298515',
'activity': [{'type': 'TILTING', 'confidence': 100}]}]
After researching a bit, I stumbled upon this article, which cleared a lot of things. However, there are some questions that still remain unanswered:-
- What does the activity type
tiltingmean? - I assumed confidence to be the probability of each task. However, often they do not add up to 100. If they do not represent probabilities what do they represent?
- What is the difference between the activity type
walkingandon foot? - How can Google possibly predict activity type between
IN_TWO_WHEELER_VEHICLEvsIN_FOUR_WHEELER_VEHICLE?!
If anyone has been able to figure it out, please let me know in comments.
Edit: There has been some discussion about these topics on this thread. A paper on Human Activity Recognition using smartphone data can be found here.
Assumptions
As
I continued to structure my pre-processing pipeline, I realized I will
have to take some assumptions to take into account all the attributes of
the data.
- The GPS is always on (A strong assumption which is later taken care of).
- The confidence interval is the probability of the activity type. This assumption helps us take into account various possible activity types for a given instance without under-representing or over-representing any particular activity type.
- Each log has two types of timestamps. (i) Corresponding to position latitude and longitude. (ii) Corresponding to the activity. Since the difference between two timestamps was usually very minute ( < 30 seconds) I safely used the timestamp corresponding to latitude and longitude for our analysis
Data Cleaning
Remember
I told how my GPS was giving Arizona, USA as the location? I did not
want those data points to significantly differ the results. Using the
longitudinal boundaries of India, I filtered out the data points
pertaining only to India.
def remove_wrong_data(data):
degrees_to_radians = np.pi/180.0
data_new = list()
for index in range(len(data)):
longitude = data[index]['longitudeE7']/float(1e7)
if longitude > 68 and longitude < 93:
data_new.append(data[index])
return data_new
Feature Engineering
Cities for each data-point
I
wanted to get the corresponding city for each given latitude and
longitude. A simple Google search got me the coordinates of the major
cities I’ve lived in i.e. Delhi, Goa, Trivandrum and Bangalore.
def get_city(latitude):
latitude = int(latitude)
if latitude == 15:
return 'Goa'
elif latitude in [12,13]:
return 'Bangalore'
elif latitude == 8:
return 'Trivandrum'
elif latitude > 27.5 and latitude < 29:
return 'Delhi'
else:
return 'Other'
data_low['city'] = data.latitude.apply(lambda x:get_city(x))
Distance
Logs
consist of latitude and longitude. To calculate distance travelled
between logs, one has to convert these values to formats that can be
used for distance related calculations.
from geopy.distance import vincenty coord_1 = (latitude_1,longitude_1) corrd_2 = (longitude_2, longitude_2) distance = vincenty(coord_1,coord_2)
Normalized Distance
Each
log consists of activity. Each activity consists of one or more
activity types along with the confidence (called as probability). To
take into account the confidence of measurement, I devised a new metric
called normalized distance which is simply distance * confidence
Data Analysis
Now comes the interesting part! Before I dive into the insights, let me just brief on some of the data attributes:-
accuracy:Estimation of how accurate the data is. An accuracy of less than 800 is generally considered high. We have therefore dropped the columns with accuracy greater than 1000day:Represents the day of the monthday_of_week:Represents the day of the weekmonth:Represents the monthyear:Represents the yeardistance:Total distance travelledcity:City corresponding to that data point
Outlier Detection
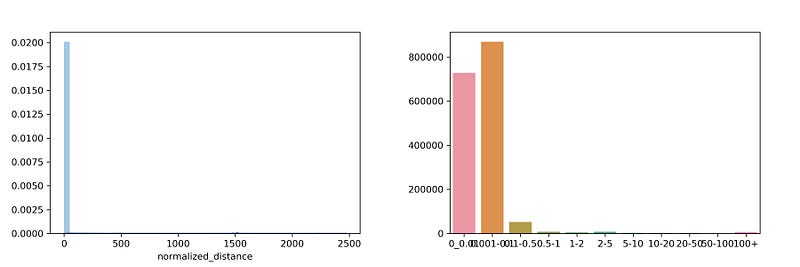
There
are total 1158736 data points. 99% of the points cover a distance less
than 1 mile. The rest 1% are anomalies generated due to poor
reception/flight mode.
To
avoid the 1% of data causing significant changes in our observations,
we’ll split the data into two based on the normalized distance.
This also ensures that we remove the points which do not obey the assumption #1 we made during our analysis
data_low = data[data.normalized_distance < 1] data_large = data[data.normalized_distance > 1]
Distance travelled with respect to the city

The data for 2018 correctly represents that majority of the time was spent at Bangalore and Trivandrum.
I
wondered how distance travelled in Delhi (my hometown) came out to be
more than the Goa, where I did my graduation. Then it hit me, I did not
have a mobile internet connection for the majority of my college
life :).
Travel Patterns in Bangalore and Trivandrum
In June 2018, I completed my internship in my previous organization (at Trivandrum) and joined Nineleaps
(at Bangalore). I wanted to know how my habits changed on transitioning
from one city to another. I was particularly interested in observing my
patterns for two reasons:
- Since I always had mobile internet while residing in these cities, I expected the representation to be an accurate representation of reality.
- I’ve spent roughly the same amount of time in two cities, hence the data will not be biased towards any particular city.

- Multiple friends and family members visiting Bangalore in the month of October resulted in a huge spike in distance travelled in vehicles.
- Initially, I was exploring Trivandrum. However, as my focus shifted to securing a full-time data science opportunity, the distance travelled drastically reduced from January to February to March.

- Vehicle usage is much higher in Bangalore between 20:00–00:00. I guess I am leaving office later in Bangalore.
- I was walking a lot more in Trivandrum! The difference in walking distance from 10:00–20:00 shows how I was living a healthier lifestyle by taking a walk after every hour or two in office.
Conclusion
There is a lot more (like this and this)
to do with your Location history. You can also explore your
Twitter/Facebook/Chrome data. Some handy tips when trying to explore
your dataset:
- Spend a significant amount of time pre-processing your data. It’s painful but worth it.
- When working with large volumes of data, pre-processing can be computationally heavy. Instead of re-running the Jupyter Cells every time, dump the post-preprocessed data into a pickle file and simply import the data when you start again.
- Initially, you might miserably fail (like me) in finding any patterns. Make a list of your observations and keep exploring the dataset from different angles. If you ever reach a point wondering whether any patterns are even present, ask yourself three questions: (i) Do I have a thorough understanding of the various attributes of data? (ii) Is there anything I can do to improve my pre-processing step? (iii) Have I explored the relationship between all the attributes using all possible visualization / statistical tools?
To get started you can use my Jupyter Notebook here.
If you have any questions/suggestions feel free to post on comments.
You can connect with me on LinkedIn or email me at k.mathur68@gmail.com.



Comments
Post a Comment